
세션 불일치 문제
Scale-out을 통해 분산 서버 환경을 구축했을 때 발생할 수 있는 가장 큰 문제점은 역시 세션 불일치 문제이다.
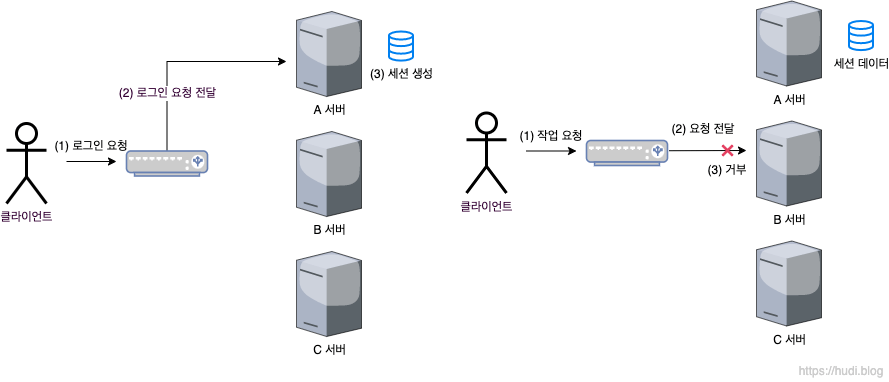
분산 서버 환경에서는 로드밸런서를 통해 트래픽을 분산하여 운영하고, 여러대의 서버는 세션 저장소를 독립적으로 가지고 있다.
만약 클라이언트가 로그인 요청을 하고 로드밸런서를 통해 요청이 A서버로 전달되면 클라이언트의 세션 정보는 A서버에 저장된다. 이후에 클라이언트의 작업 요청이 A서버가 아닌 다른 서버로 전달된다면 해당 서버에는 세션 정보가 존재하지 않기 때문에 문제가 발생한다.
이를 세션 불일치 문제라고 한다.
세션 불일치 문제를 해결하기 위해서 크게 3가지 방법을 적용해볼 수 있다.
1. Sticky Session 방식
- 해당 클라이언트의 요청과 응답을 처리할 서버를 고정시키는 방식이다.
- 1번 클라이언트의 요청은 모두 A서버에, 2번 클라이언트의 요청은 모두 B 서버에서 처리하도록 고정하면 세션 불일치 문제를 해결할 수 있다.
- 문제점
- 특정 서버에 트래픽이 집중 : 특정 클라이언트의 요청이 많아진다면 하나의 서버에 트래픽이 집중될 수 있고 결국 본래의 목적인 로드밸런싱의 효과가 없어질 수 있다.
- 세션 정보의 유실 가능성 - 세션 정보를 가지고 있는 서버에 장애가 발생하면 세션 정보가 모두 유실되는 문제가 있다.
2. Session Clustering 방식
- 특정 서버에서 세션이 생성될 때 다른 서버의 세션 저장소로 복제하는 방식이다.
- A서버에 세션이 저장될 때 B, C 서버에 복제하여 같은 세션 정보를 갖고있다면 트래픽이 몰릴 걱정 없이 세션 불일치 문제를 해결할 수 있다
- 문제점
- 비효율적인 메모리 사용 : 같은 정보를 모든 세션 저장소에 저장하는 것
- 네트워크 요청 트래픽 증가 : 데이터의 변경이 발생할 때마다 복제 작업을 위한 네트워크 요청 증가
3. Session Storage 방식
- 외부에 별도의 세션 저장소를 두고 서버들이 이를 공유하여 세션 불일치 문제를 해결하는 방식이다.
- 일반적인 Disk 데이터베이스(MySQL, 오라클 등)은 데이터의 영속성을 위해 사용하지만,
세션 정보는 영속성을 보장할 필요가 없기 때문에 비교적 입출력 속도가 빠른 In-memory 데이터베이스를 사용한다 - 트래픽 부하, 비효율적인 메모리 사용, 네트워크 트래픽 증가 문제 없이 세션 불일치 문제를 해결할 수 있다.
- 하지만 세션 저장소에 장애가 발생하면 모든 세션 정보를 잃어버리는 문제가 있다.
- 마스터-슬레이브 복제를 활용하여 동일한 세션 저장소를 하나 더 구축하는 식으로 해당 문제를 보완할 수 있다.
Redis 선택
프로젝트에서 세션 저장소 방식을 사용해서 세션 불일치 문제를 해결하기로 결정했으면 이제 세션 저장소로 활용할 데이터베이스를 선택해야 한다.
위에서 설명한대로 세션 저장소는 영속성을 보장할 필요가 없기 때문에 비교적 속도가 빠른 인메모리 데이터베이스를 선택하게 된다. 가장 대표적인 In-memory DB인 Redis와 Memcached를 비교해 보자
| Redis | Memcached | |
| 저장소 | In Memory Storage | |
| 저장 방식 | Key-Value | |
| 데이터 타입 | String, Set, Sorted Set, Hash, List | String |
| 데이터 저장 | Memory, Disk | Only Memory |
| 메모리 재사용 | 메모리 재사용 하지 않음(명시적으로만 데이터 삭제 가능) | 메모리 부족시 LRU 알고리즘을 이용하여 데이터 삭제 후 메모리 재사용 |
| 스레드 | Single Thread | Multi Thread |
| 캐싱 용량 | Key, Value 모두 512MB | Key name 250 byte, Value 1MB |
Memcached 는 멀티 스레드를 지원하고 Redis에 비해 적은 메모리를 사용한다.
Redis는 다양한 자료구조를 지원하고 Replication, 스냅샷, Pub/Sub 같은 여러 기능들을 제공한다.
서비스의 설계에 따라 적절히 선택하면 된다.
일반적으로 데이터 읽기 성능은 Redis가 데이터 쓰기 성능은 Memcached가 더 좋다고 알고있다. 세션 데이터는 생성하는 것보다 읽는 작업이 더 많은 데이터이기 때문에 이런 관점에서는 Redis가 더 적절할 수 있다.
또한 다양한 자료구조를 지원하기 때문에 이후에 캐시 저장소로 활용하기에도 Redis가 적절하다고 생각했다.
Redis는 스프링에서 API를 지원하기 때문에 의존성 빌드를 통해 간단하게 적용시킬 수 있다.
관련 레퍼런스도 Memcached 보다 훨씬 풍부하기 때문에 프로젝트 적용에 조금 더 용이할 것이라고 판단하여 Redis를 적용하기로 결정했다.
실제 적용 과정은 다음 포스트에서
참고
- https://hudi.blog/session-consistency-issue/
- https://deveric.tistory.com/65
- https://velog.io/@sileeee/Redis-vs-Memcached
'트러블슈팅' 카테고리의 다른 글
| [Spring] Redis 캐시 적용하기 (2/2) (0) | 2023.10.22 |
|---|---|
| [Spring] Redis 캐시 적용하기 (1/2) (1) | 2023.10.19 |
| [Spring] Redis를 통한 세션 불일치 문제 해결 (2/2) (0) | 2023.10.14 |
| [Spring] 재고처리 동시성 이슈 해결하기 (2/2) (0) | 2023.07.22 |
| [Spring] 재고처리 동시성 이슈 해결하기 (1/2) (0) | 2023.07.22 |